Распознавание образов
Распознавание образов
Теория и принципы построения систем, способных различать предметы, явления и ситуации и группировать их в образы.
Что есть что!
Одна из удивительнейших способностей человека - способность узнавать - ни у кого не вызывает удивления. Мы сразу, только увидев, узнаем, что перед нами корабль, бабочка, чашка, слон и т. п. Узнаем сразу и безошибочно, будь то сам "оригинал" или его уменьшенное или увеличенное изображение.
Удивляет нас не это Потрясающее свойство, наоборот, потерю его считают сверхъестественным, рассматривают как болезнь...
Мы живем в мире, окружающем нас различными образами - явлениями, предметами, ситуациями. И когда мы их воспринимаем, то обязательно разбиваем на группы похожих - классифицируем. Подчас в группе похожих оказываются очень разные, значительно отличающиеся один от другого предметы, но в чем-то они обязательно схожи, одинаковы в каких-то определенных принципах.
Возьмем буквы алфавита. Каким бы "трудным" почерком ни были они написаны, мы всегда узнаем, что буква "у" - это буква "у", буква "д" - это буква "д", буква "з" - это буква "з"...
Или сопоставим такие разные рисунки, как, допустим, портрет человека, сделанный рукой мастера, и детский рисунок. При разительном отличии налицо и сходство: каждый понимает - ив том и в другом случае художники, и взрослый и ребенок, изобразили человека.
Нет нужды приводить примеры еще. Зачем объяснять понятное? - можете вы возразить.
Понятное? Так ли это?
Способностью узнавать человек обладает испокон веков. И все-таки до сего времени ученые в точности не знают, как же человек узнает. Как он по каким-то едва уловимым признакам, зачастую неполным характеристикам "складывает" в своем мозгу понятие образа? Того образа, который в восприятии окружающего мира, в процессах познания мира, раскрытия его тайн играет важнейшую роль.
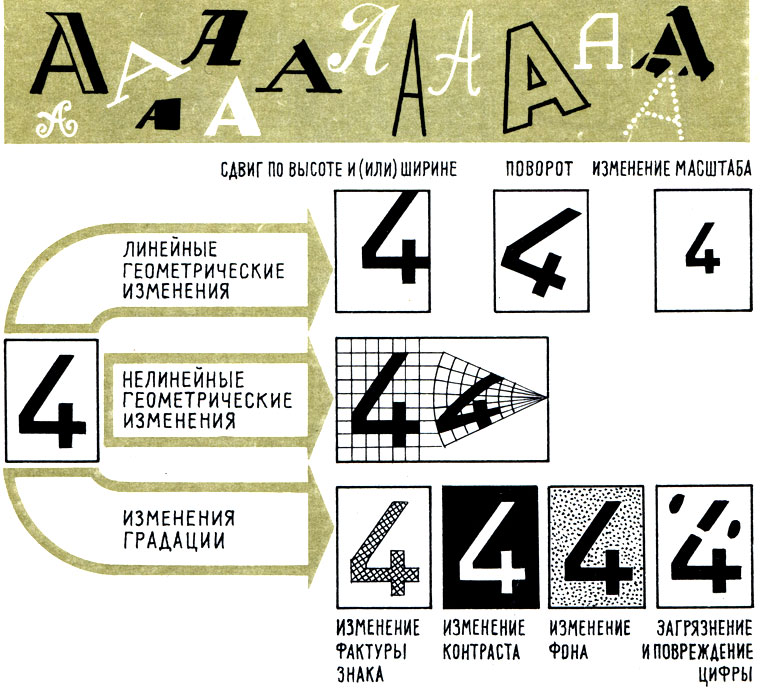
Все фигуры, изображенные вверху, мы называем буквой 'А', несмотря на большое различие в их начертании. Любой знак письменности - буква или цифра - при написании может подвергнуться всевозможным искажениям
И здесь мы опять сталкиваемся с парадоксом, которых отнюдь не мало, когда речь заходит о загадках человеческого мозга, человеческой психики: не зная, как человек "строит" образ, ученые "знают цену" этой способности. Они утверждают, что восприятие явлений действительности в форме образов дает возможность более экономно использовать память. Ведь образ освобождает нас от необходимости запоминать несчетное множество конкретных предметов, явлений. Именно образ позволяет нам пользоваться накопленным ранее опытом.
Ученые весьма авторитетно говорят, что, не обладая способностью группировать объекты в образы, мы становились бы в тупик перед каждым новым явлением (совсем как вычислительная электронная машина). Ведь ни один предмет, ни одно явление никогда не бывает точным повторением, точной копией встречавшихся нам ранее!
Чем же достигается эта наша способность, которую трудно переоценить? Конечно, обучением. Обучаясь, накапливая опыт, человек классифицирует виденное, распознает образы.
И вот тут перед учеными встает вопрос, совершенно неожиданный для непосвященных и совершенно закономерный для кибернетиков: нельзя ли научить электронные вычислительные машины моделировать процесс распознавания образов?
В качестве ответа хочется привести убедительную цитату из специального энциклопедического издания:
"Принципиальная разрешимость задач распознавания образов вытекает из наличия способности распознавания образов у человека и других живых организмов. В живой природе способность классифицировать сложные ситуации приобретается обучением, поэтому целесообразно использовать принцип обучения для создания классифицирующих автоматов. Их оказывается возможным создать даже в тех случаях, когда конструктору заранее не известны признаки, лежащие в основе классификации, но он располагает достаточным числом примеров отнесения ситуации к определенному классу".
Итак, раз в принципе создать узнающую машину возможно, то ученые во всем мире стали искать пути, как принцип воплотить в действие.
С легкой руки американского кибернетика Ф. Розенблюта, создавшего один из таких первенцев, их стали называть "персептронами".
Персептроны - машины читающие. Долго и трудно давался ученым "ликбез" - ликвидация безграмотности - машин. И вот появились они, эти "грамотные" автоматы. По правде говоря, они мало чем отличаются по внешности от своих "неученых" братьев: все тот же привычный узкий металлический шкаф. Только с "глазами"-экранами. Этот нацеленный на текст оптический глаз фотоэлемента и позволяет машине "читать", распознавать образы букв.
Попробуем разобраться, как работает персептрон.
Сначала познакомимся с американской машиной. Впереди у нее экран - искусственная сетчатка из четырехсот фотоэлементов. Экран воспринимает образ. Электрические сигналы, порожденные в сетчатке при восприятии образа, бегут к первому этажу "нейронов" - электронных элементов, моделирующих нервную ячейку. Над ними еще один "нейрон" - главный. К нему подведены входные сигналы нижнего этажа. И от специального устройства идут сигналы-"наказания". Такова принципиальная схема персептрона Розенблюта.
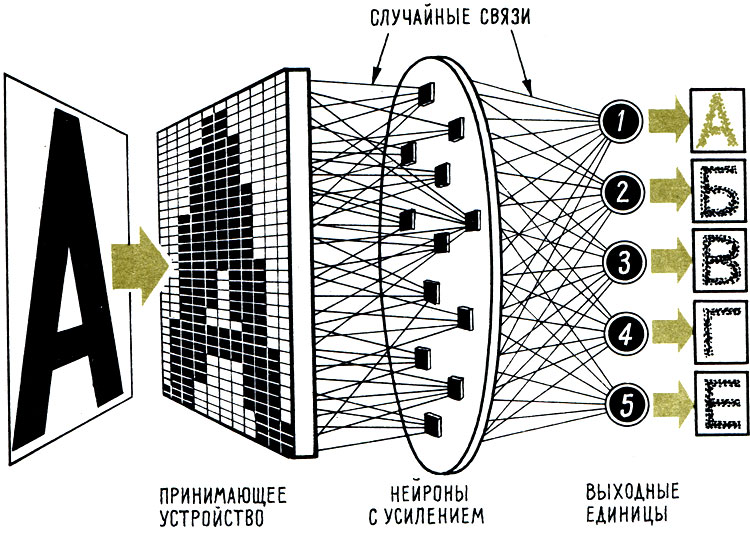
Так работает персептрон. После многократного повторения процесса обучения букве 'А' и 'усвоения' курса обучения систему 'настраивают' на букву 'Б' и т. д
Вот перед экраном поочередно поставили несколько букв. Естественно, они разных начертаний. Но машина узнает их, уверенно отличает "а" от "б", "б" от "в" - любую букву от любой другой.
Долго ли обучали машину этому искусству? Долго. Вначале персептрон часто ошибался, и тогда его "наказывали". Делалось это просто. Если машина ошибалась, оператор нажимал кнопку "наказания", и сигналы, поступавшие к главному "нейрону", порожденные неправильным ответом, ослаблялись. Затем машине снова показывали фигуры и снова оценивали ответ. И когда все сигналы собирались на "совет" к главному "нейрону", то у "провинившихся" было меньше голосов.
Так машина на собственных ошибках училась распознавать образы.
Советские ученые разработали совершенно другой принцип распознавания образов. В его основе лежит гипотеза "компактных множеств". Познакомимся с ней.
Учитель хочет научить малыша распознавать образ - букву А. Для этого он объясняет ему, по каким конкретным признакам можно узнать эту букву. Например, по двум наклоненным палочкам с перекладиной посредине.
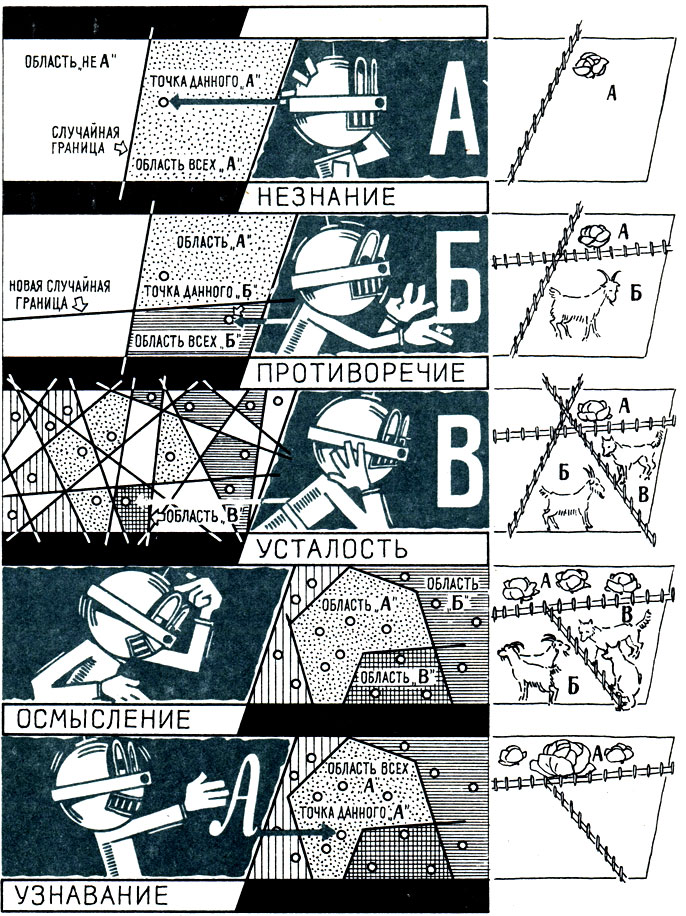
Узнающая машина, основанная на принципе 'компактных множеств'. Точка, соответствующая данной букве, попадает в определенную область. Машина, помня, точки какого образа занимают эту область, определит, какая это буква
Вспомните, как в рассказе А. Куприна "Олеся" герой повествования учил крестьянина Ярмолу писать фамилию. Первая буква фамилии - П - у Ярмолы была известна под названием "два стояка и сверху перекладина", буква О называлась "колесо", а буква К была известна как "палка, а посредине палки кривуля хвостом набок".
Но учитель может поступить иначе. Он может положить перед учеником 20 разных букв А и сказать, что все они - буквы А. Потом покажет 20 букв Б, 20 букв В и т. д. И ученик начнет уверенно различать буквы. Он создал для себя зрительный образ каждой буквы и узнает их, как бы они ни были написаны.
Гипотеза "компактных множеств" исходит из предположения, что при показе буквы А в сознании человека сразу отпечатывается точка - образ этой буквы. Затем человеку показывают ту же букву, но написанную иным почерком. Снова отпечатывается точка где-то вблизи первой. Третья, десятая, сотая по-разному написанная буква А отпечатывает всё новые точки в сознании. Но все они располагаются кучно, компактно.
А кучки точек, возникших при показе разно написанных Б, образуют другое компактное множество. Так и с другими образами букв. И каждое множество отделяется от другого четкими границами - их разделяет своего рода забор.
"А нужна ли узнающая машина? - спросите вы. - Ведь "электронные вычислители" работают молниеподобно. Им ничего не стоит сравнить по сотням, тысячам признаков различные образы с "эталонами", которые можно ввести в машинную "память".
Это все так. Но не стоит забывать, что машинная "память", ее объем, всегда ограничена. И потом, нет ни одного образа в точности, в мельчайших деталях похожего на другой. Оказывается, нет даже, если строго обращать внимание на признаки, как это надо делать для вычислительной машины, двух совершенно одинаковых печатных типографских букв. Что же, описывать каждый раз каждый образ с скрупулезной точностью? Это непосильная, практически невыполнимая задача.
И еще одна трудность: работа машины "по эталонам" невозможна без участия человека. Именно человек должен и описать эталон, и дать целый набор признаков для сравнения с эталоном. А ведь ученые поставили задачу самую машину научить различать образы. И поставили не праздно, не для того, чтобы решить только теоретически интересную проблему, но и использовать узнающие машины на практике.
Для практических же целей такие машины очень нужны.
Вот яркий пример, когда персептрон мог бы помочь. Представьте себе геолога, который по данным геологической разведки должен определить, нефтеносный ли перед ним пласт. Геолог-интерпретатор - есть такая специальность - разбирается в данных об особенностях пласта, оценивает его электрические, радиационные и геометрические характеристики. Нефтеносному пласту соответствует буквально океан совокупностей этих характеристик. Столько же характеристик у водоносного пласта, от которого интерпретатор должен отличить нефтеносный. Трудность задачи возрастает непомерно еще и оттого, что нет в геофизике правил, предписывающих относить пласт либо к водоносному, либо к нефтеносному. И отсюда идут ошибки. Очень много ошибок - от 5 до 80%!
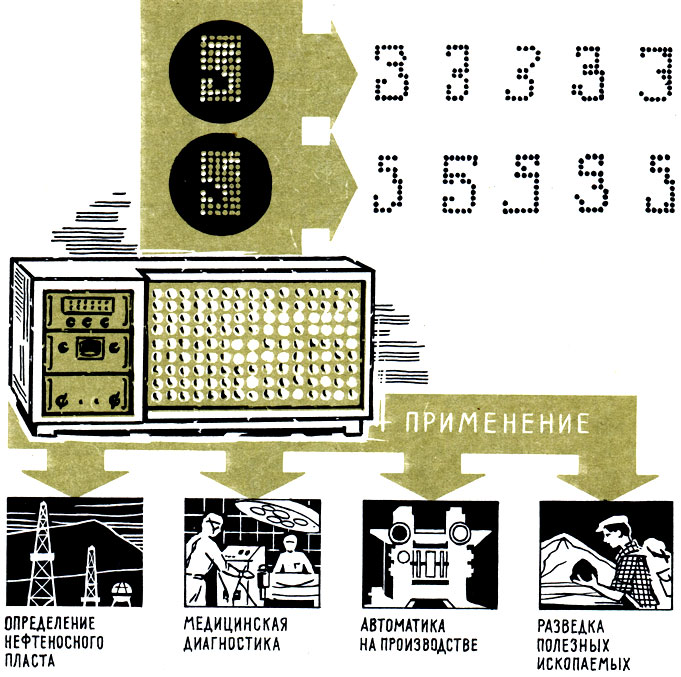
Обучение машин распознаванию образов находит большое применение в науке, технике и на производстве
Поэтому не мудрено, что задумываются, нельзя ли создать классифицирующую автоматическую систему. Она по определенным признакам могла бы с несравненно более высокой точностью решить задачу о нефтеносности пласта.
А как изменился бы характер информационных автоматов! Машина "читала" бы с листа. Для нее не надо было бы переводить текст "с человеческого языка на машинный". Она дала бы возможность общаться с ней непосредственно.
При помощи узнающей машины можно будет автоматизировать запись справочных материалов для электронных машин, которые оцениваются ни много ни мало миллиардами слов; автоматизировать процесс сортировки писем на почте; обрабатывать банковские документы; автоматизировать типографский набор и т. п.
Как нетрудно догадаться, намного облегчится и машинный перевод.
Есть и другая сторона в применении узнающих машин. Начав свой путь от подражания человеческой способности к образному восприятию окружающего мира, персептроны помогут раскрыть механизм, по которому человек "строит" образ, классифицирует явления, события, предметы.
К решению проблемы распознавания образов, проблемы важной принципиально и практически, ученые разных специальностей идут различными путями. Это неизбежно и оправданно: создание узнающих машин - задача чрезвычайно трудная.

Что есть что!
|
ПОИСК:
|
При копировании материалов проекта обязательно ставить ссылку на страницу источник:
http://roboticslib.ru/ 'Робототехника'