5.5. Открытые коллективы. Иерархия
Коллективы алгоритмов, в которых применяется открытый буфер только для "пуска" коллектива, обычно относят к закрытым. Мы будем говорить об открытых коллективах, имеющих и другие открытые буфера, называемые существенными.
Наличие открытого буфера может вызывать безрезультатную остановку коллектива алгоритмов. Внося искусственно изменения в состояние открытого буфера, можно добиться продолжения процесса и, поступая так нужное число раз, довести процесс до получения результата. Если, по-разному воздействуя на буфер, можно получать не равные между собой результаты, то открытый буфер называется существенным. Наличие существенного открытого буфера приводит к тому, что коллектив алгоритмов перестает обладать свойством однозначности результата по отношению к исходному данному.
Если для закрытых коллективов справедлива теорема о том, что каждый из них эквивалентен некоторому одиночному алгоритму, то для открытого коллектива это не так (из-за его неоднозначности).
Но посмотрим на открытый коллектив алгоритмов с другой стороны. Будем считать, что операнд X (исходное данное) является некоторым параметром, а последовательность элементов информации b = (b1, b2, ..., bn), которые мы вводим в буфер для того, чтобы совокупный процесс привел к искомому результату (обозначим его Y), примем за значение аргумента. Повторяю, значениями аргумента будем считать не отдельные данные, а их последовательности. Тогда окажется, что каждую последовательность b (при фиксированном X) коллектив алгоритмов отображает на некоторый результат Y. И при этом отображение будет однозначным.
Каждую последовательность b будем называть серией*.
* (Не смешивать с серией критических отрезков процесса.)
Если коллектив алгоритмов имеет несколько открытых существенных буферов, то он индуцирует функцию от многих переменных (зависящую от параметра X). Значениями аргументов этой функции будут серии данных.
Обычно в роботе под параметром X понимают ту информацию, которая хранится в его памяти (запоминающем устройстве), а результат Y расчленяют на части, одну из которых считают новым значением X, другую рассматривают как управляющую информацию и передают эффекторам, а третью вовсе стирают как ненужную (это "отходы производства").
После получения результата и выделения из него нового значения X, выполнение коллектива алгоритмов повторяют и т. д. Таким образом, сигналы рецепторов вместе с информацией, накопленной в памяти, перерабатываются в управляющие сигналы и новое состояние памяти.
Так как при управлении роботом существенное значение имеет своевременность реакции, то в состав коллектива алгоритмов иногда включают алгоритм, играющий роль рецептора, называемый генератором времени. Задаваемое им "время" называют алгоритмическим временем.
Генератор времени часто называют алгоритмическими часами. Но такой термин неудачен. Часы, по всеобщему мнению, являются измерительным прибором, который позволяет измерять время. Я не стану оспаривать эту общепринятую точку зрения, но замечу, что ничего общего с измерением времени генерация алгоритмического времени не имеет.
Пусть 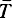 - некоторая подконструкция операнда, которая может принимать состояния
- некоторая подконструкция операнда, которая может принимать состояния 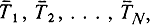 где N - очень большое число, и пусть θ - процедура, которая для любого i<N преобразует
где N - очень большое число, и пусть θ - процедура, которая для любого i<N преобразует 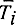 в
в 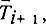 а кроме того
а кроме того 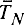 и
и 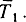 Генератором времени называется алгоритм
Генератором времени называется алгоритм
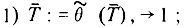
Другие алгоритмы коллектива могут обращаться в подконструкции только для чтения, и таким способом они (если это надо) "узнают", каково алгоритмическое время. Если подконструкция никак не защищена, то в момент обращения к ней нескольких алгоритмов происходит не поддающаяся учету случайная задержка всех процессов, кроме одного. При этом результат, который прочитает тот или иной алгоритм, непредсказуем. Чтобы алгоритмы коллектива между собой не "боролись" за доступ к , следует организовать очередь из алгоритмов-пользователей. Но это не устранит непредсказуемости результата считывания. Если же подконструкцию организовать как буфер, защищенный регулирующими предикатами, то непредсказуемость исчезнет, но генератор времени будет останавливаться и ждать, пока алгоритмы-клиенты читают "который час". Разработчик коллектива алгоритмов должен решать, что лучше или, вернее, что хуже.
Обычно в качестве берут ячейку, которая может принимать последовательные числовые значения, т. е. удовлетворяющую условию 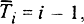 и тогда генератор времени принимает вид
и тогда генератор времени принимает вид
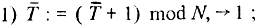
Здесь выражение 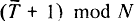 называется сложением по модулю N и равно остатку от деления суммы
называется сложением по модулю N и равно остатку от деления суммы 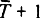 на N. В нашем случае
на N. В нашем случае
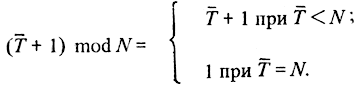
Можно построить генератор времени так, чтобы "столкновение" алгоритмов при чтении было полностью исключено. Например, для каждого алгоритма Аi отвести свою ячейку связи с часами Ti. Это похоже на ситуацию, в которой каждому прохожему предоставлялся бы отдельный циферблат на уличных часах только для того, чтобы, определяя время, прохожие между собой не передрались... При этом генератор времени может иметь вид:
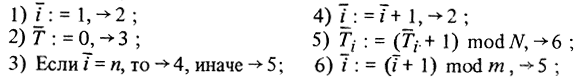
Легко сообразить, что такие "часы" на разных "циферблатах" одно и то же будут показывать не одновременно. Возможность столкновений между алгоритмами и генератором и здесь не устранена.
Точное алгоритмическое время алгоритмы коллектива не могут считывать из-за того, что в коллективе возникает "борьба" за обращение к "часам" . Но если для отсчета времени взята ячейка, принимающая последовательные целочисленные значения, то границы интервала разброса можно определить и тогда будет известно, с какой ошибкой определяется алгоритмическое время поступления данных или выдачи результата.
В тех случаях, когда коллектив алгоритмов реализован в виде некоторого физического устройства, можно установить экспериментальным способом зависимость, существующего между алгоритмическим и физическим временем. Соотношение это должно быть таково, чтобы робот действовал в так называемом реальном времени, т. е. чтобы реакции на внешние воздействия вырабатывались достаточно быстро. Иначе управляющее устройство робота неэффективно. Читателю понятно, что управляющее устройство при нашем подходе - это физическая модель открытого коллектива алгоритмов.
Наряду с регулирующими предикатами, вернее с ожиданием регулирующего предиката, можно допустить и другие бесконфликтные способы обращения к буферу. Я имею в виду такой практически важный прием, как спаривание буфера с собственной подконструкцией алгоритма. Поясню этот прием.
Прежде всего замечу, что каждый алгоритм может иметь много собственных подконструкций. До сих пор я не подчеркивал этого факта. В предыдущих примерах встречалась подконструкция 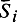 . В действительности это может быть любая из собственных подконструкций и даже совокупность всех собственных подконструкций. В последнем случае наши примеры приобретают очень частный характер, с которым я мирился ради простоты, учитывая возможность его устранения включением дополнительных приказов.. Ниже нам просто нужно, чтобы собственных подконструкций было несколько (хотя бы две).
. В действительности это может быть любая из собственных подконструкций и даже совокупность всех собственных подконструкций. В последнем случае наши примеры приобретают очень частный характер, с которым я мирился ради простоты, учитывая возможность его устранения включением дополнительных приказов.. Ниже нам просто нужно, чтобы собственных подконструкций было несколько (хотя бы две).
Пусть теперь 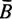 - некоторый буфер,
- некоторый буфер, 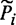 - регулирующий предикат, заданный на этом буфере и соответствующий алгоритму Ai, а
- регулирующий предикат, заданный на этом буфере и соответствующий алгоритму Ai, а 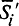 - одна из собственных подконструкций алгоритма Ai. Тогда возможна следующая семантическая схема обращения к :
- одна из собственных подконструкций алгоритма Ai. Тогда возможна следующая семантическая схема обращения к :
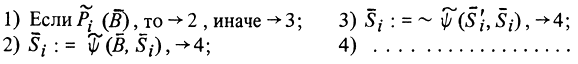
Эта схема предусматривает проверку истинности регулирующего предиката . Если предикат имеет логическое значение "истина", то выполняется приказ 2, смысл которого в том, что информация из буфера В переносится в подконструкцию , после чего, начиная с приказа 4, продолжается выполнение алгоритма Ai. Если же регулирующий предикат имеет логическое значение "ложь", то аналогичная по своей структуре (но другая по смыслу) информация, в силу приказа 3 переносится в собственную подконструкцию из i и, как в предыдущем случае, продолжается выполнение алгоритма, начиная с приказа 4. Буфере должен быть открытым. Сущность описанного приема в том, что если внешнее воздействие не закончено к моменту обращения алгоритма к i, то вместо ожидания информации, которая может поступить в буфер, но нарушает требования режима реального времени, алгоритм Ai из подконструкций i получает запасенную ранее, может быть, несколько устаревшую, но близкую к нужной информацию.
Мы уже говорили, что буферы можно применять для запуска алгоритмов и даже их коллективов (см. с. 84). Эту возможность легко использовать для того, чтобы один алгоритм (или коллектив) разрешал или запрещал функционировать другому. Пусть буфер а доступен алгоритму А по записи, а алгоритму В - по чтению и В содержит приказ "Ожидать α = 1", причем вначале а = 0. Достигнув этого приказа, В остановится и будет "ожидать" до тех пор, пока алгоритм А не выполнит приказ
Тот же А, своим приказом
заставит алгоритм В остановиться при очередном обращении к α.
При такой связи между алгоритмами (коллективами алгоритмов) В и А говорят, что В подчинен А.
Если коллектив алгоритмов К можно разбить на подколлективы так, что каждый из них, кроме одного (главного), подчинен одному и только одному подколлективу, то K называют иерархическим.
Иерархическая структура позволяет четко распределить функции между подколлективами.
Передача подчиненным педколлективом своих результатов старшему допустима, но без задержки процесса выполнения старшего. Один из приемов такой передачи заключается в том, что старший наделяется возможностью "маскировать" буфер, доступный младшему по записи. Допустим, что младший обращается к старшему, заменяя в буфере γ код 0 кодом 1. Тогда для старшего предусматривают собственную ячейку δ, которая может содержать либо 0, либо 1, и в старшем ставят пару приказов
|
ПОИСК:
|
При копировании материалов проекта обязательно ставить ссылку на страницу источник:
http://roboticslib.ru/ 'Робототехника'